Get a customized LLM which understands your business and needs
- G B
- Feb 15
- 5 min read

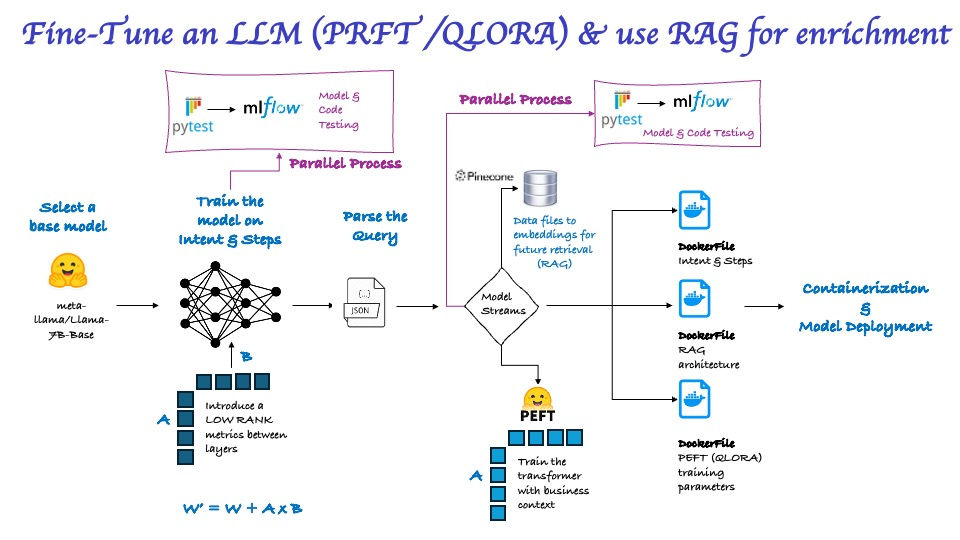
Fine-Tune Open source Transformer
Fine-Tune open source transformers to develop LLM's using techniques like PEFT, LORA/QLORA. Implemented techniques like PyMuPDF, pdfplumber, PDFMiner, PyMuPDF, pdfplumber, Whisper to extract and prepare data for LLM training.
Loading a Pre-Trained Transformer Model Using Hugging Face
Transformer models have revolutionized Natural Language Processing (NLP) by enabling contextual understanding of text. One of the most widely used transformer models is BERT (Bidirectional Encoder Representations from Transformers), which can be leveraged for various NLP tasks such as text classification, named entity recognition, and question answering.
In this article, we demonstrate how to load a pre-trained BERT model using Hugging Face’s transformers library.
# Choose a open source transformer
from transformers import AutoTokenizer, AutoModel
import torch
# ✅ Load Pre-Trained BERT Model
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
Establishing Embedding Storage & Retrieval with Pinecone
Vector databases like Pinecone enable efficient storage and retrieval of high-dimensional embeddings, making them essential for semantic search, recommendation systems, and LLM-powered applications.
The following code initializes Pinecone, creates an index named "trade-terms", and configures it with 768 dimensions (matching typical transformer embeddings) using the cosine similarity metric for efficient retrieval.
✅Establish Embedding Storage & Retrieval Capability
from pinecone import Pinecone, ServerlessSpec
# Initialize Pinecone with your API key
pc = Pinecone(api_key="YOUR_API_KEY")
index_name = "trade-terms"
pc.create_index(
name = index_name,
dimension = 768,
metric = "cosine",
spec = ServerlessSpec(
cloud = 'aws',
region = 'us-east-1'
)
)
Generating BERT-Based Embeddings
BERT embeddings capture the contextual meaning of words and sentences, making them useful for tasks like semantic search, document clustering, and text classification. Below is a simple function to generate BERT-based embeddings using a pre-trained model.
✅ Function to Generate BERT-Based Embeddings
def generate_bert_embedding(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512, padding=True)
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
# ✅ Store Business Terms with BERT Embeddings in Pinecone
for term, definition in business_terms.items():
text = f"{term}: {definition}"
vector = generate_bert_embedding(text)
metadata = {"term": term, "definition": definition}
index.upsert([(term, vector.tolist(), metadata)])
print("✅ Business Terms Stored in Pinecone Using BERT Embeddings")
Generating Training Data for AI Model Fine-Tuning
To improve the AI model’s understanding of trade and pricing calculations, this script generates structured training examples based on a dataset (df). It creates question-answer pairs covering key business metrics such as discount percentage, trade rate, profit unit, margin percentage, unit lift, incremental profit, and ROI.
Each training example follows a structured format, dynamically inserting real data values into mathematical formulas. The generated data is then saved as a JSON file (formula_training_data.json) for use in fine-tuning NLP models or training an AI assistant specialized in business analytics.
✅ Key Benefits:
Automates training data creation for AI-powered business decision-making.
Ensures consistent formula-based responses using dynamically extracted values.
Enhances AI model accuracy in handling financial and trade-related queries.
🚀 With this approach, businesses can train AI assistants to answer trade-related queries with real-time data-driven insights!
# Generate Training Examples
training_data = []
for _, row in df.iterrows():
training_data.append({
"question": f"If Base_Price is {row['Base_Price']} and Price is {row['Price']}, what is the Discount?",
"answer": f"Discount = (Base_Price - Price) / Base_Price * 100 = "
f"({row['Base_Price']} - {row['Price']}) / {row['Base_Price']} * 100 = {calculate_discount(row)}%"
})
training_data.append({
"question": f"If $_Total_Trade_Unit is {row['$_Total_Trade_Unit']} and List_Price is {row['List_Price']}, what is the Trade Rate?",
"answer": f"Trade_Rate = Trade_Unit / List_Price = {row['$_Total_Trade_Unit']} / {row['List_Price']} = {calculate_trade_rate(row)}"
})
training_data.append({
"question": f"If List_Price is {row['List_Price']}, COGS_Unit is {row['COGS_Unit']}, EDLP_Trade_$_Unit is {row['EDLP_Trade_$_Unit']}, "
f"and Var_Trade_$_Unit is {row['Var_Trade_$_Unit']}, what is the Profit Unit when Week_Type is '{row['Week_Type']}'?",
"answer": f"Profit_Unit = List_Price - COGS_Unit - EDLP_Trade_Unit = {row['List_Price']} - {row['COGS_Unit']} - {row['EDLP_Trade_$_Unit']} "
f"= {calculate_profit_unit(row)}"
})
training_data.append({
"question": f"If Base_Price is {row['Base_Price']}, List_Price is {row['List_Price']}, EDLP_Trade_$_Unit is {row['EDLP_Trade_$_Unit']}, "
f"Var_Trade_$_Unit is {row['Var_Trade_$_Unit']}, and Week_Type is '{row['Week_Type']}', what is the Margin Percentage?",
"answer": f"Margin_% = (Base_Price - List_Price + EDLP_Trade_Unit) / Base_Price = "
f"({row['Base_Price']} - {row['List_Price']} + {row['EDLP_Trade_$_Unit']}) / {row['Base_Price']} = {calculate_margin(row)}"
})
training_data.append({
"question": f"If %_Unit_Lift is {row['%_Unit_Lift']}, what is the Lift Percentage?",
"answer": f"Lift_% = {calculate_lift(row)}"
})
training_data.append({
"question": f"If $_Inc_Profit is {row['$_Inc_Profit']}, what is the Incremental Profit?",
"answer": f"Inc_Profit = {calculate_inc_profit(row)}"
})
training_data.append({
"question": f"If %_ROI is {row['%_ROI']}, what is the ROI?",
"answer": f"ROI = {calculate_roi(row)}"
})
# ✅ Save Training Data as JSON
training_file = "./formula_training_data.json"
with open(training_file, "w") as f:
json.dump(training_data, f, indent=4)
print(f"✅ Training Data Saved Successfully at: {training_file}")
Loading and Tokenizing Training Data for AI Model Training
This script loads pre-generated training data from a JSON file (formula_training_data.json) and prepares it for AI model training. The dataset contains question-answer pairs related to trade and pricing formulas, which are then tokenized using a transformer-based tokenizer for NLP tasks.
Key Steps in the Process:
Load Training Data: Uses datasets.load_dataset() to import the JSON dataset into a structured format.
Tokenization: Converts both questions and answers into numerical token sequences, ensuring truncation and padding for uniform input lengths.
Labeling for Classification: The tokenized answer is mapped as a classification label for supervised learning.
Batch Processing: The dataset.map() function applies tokenization across the dataset efficiently.
✅ Key Benefits:
Prepares the dataset for training a transformer-based NLP model.
Ensures compatibility with models like BERT, GPT, or T5 for fine-tuning.
Optimizes text for sequence classification by structuring inputs and labels properly.
🚀 This structured pipeline allows AI models to understand and answer business-related queries with mathematical precision!
from datasets import load_dataset
# ✅ Load Existing Training Data
training_file = "./formula_training_data.json"
dataset = load_dataset("json", data_files=training_file)
# ✅ Function to Tokenize for Classification
def tokenize_function(example):
inputs = tokenizer(example["question"], truncation=True, padding="max_length", max_length=512)
labels = tokenizer(example["answer"], truncation=True, padding="max_length", max_length=512)
inputs["labels"] = labels["input_ids"][0] # ✅ Convert to a single classification label
return inputs
# ✅ Apply Tokenization
tokenized_dataset = dataset.map(tokenize_function, batched=True)
print("✅ Tokenization for Sequence Classification Completed!")
Optimizing Model Training with LoRA (Low-Rank Adaptation)
This script applies LoRA (Low-Rank Adaptation) to a pre-trained transformer model to enable efficient fine-tuning with lower memory usage. Instead of updating all model parameters, LoRA adds low-rank adapters to specific layers, reducing computational costs while maintaining performance.
Key Steps in the Process:
1️⃣ Define LoRA Configuration
r=4: Controls the rank of the low-rank matrices (smaller = lower memory usage).
lora_alpha=16: Scaling factor for the adapter weights.
lora_dropout=0.05: Adds dropout to prevent overfitting.
target_modules=["query", "key", "value", "dense"]: Specifies which BERT layers to modify.
task_type="CAUSAL_LM": Sets the model type for causal language modeling.
2️⃣ Apply LoRA to the Model
get_peft_model(model, lora_config): Wraps the existing transformer model with LoRA adapters, enabling efficient training with fewer parameters.
✅ Key Benefits:
Reduces GPU memory usage while fine-tuning large models.
Maintains model accuracy with minimal parameter adjustments.
Enables faster training compared to full fine-tuning.
🚀 This technique is ideal for fine-tuning transformer models like GPT, BERT, or LLaMA on custom datasets with limited computational resources.
from peft import LoraConfig, get_peft_model
import torch
lora_config = LoraConfig(
r=4, # Lower rank for low memory usage
lora_alpha=16, # Scaling factor
lora_dropout=0.05, # Dropout to prevent overfitting
bias="none",
target_modules=["query", "key", "value", "dense"], # ✅ Updated for BERT
task_type="CAUSAL_LM"
)
# ✅ Apply LoRA to Model
model = get_peft_model(model, lora_config)
training_args = TrainingArguments(
output_dir="./bert_formula_finetuned",
evaluation_strategy="no",
save_strategy="epoch",
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=2,
learning_rate=5e-5,
weight_decay=0.01,
logging_steps=10,
save_total_limit=1,
remove_unused_columns=False, # 🔥 Fixes the error by keeping dataset columns
report_to="none"
)
print("✅ Training Arguments Updated!")
from transformers import Trainer
# ✅ Initialize Trainer with Tokenized Dataset
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"]
)
# ✅ Start Fine-Tuning
trainer.train()
print("✅ BERT Fine-Tuned on Mac M1 with LoRA (No bitsandbytes)!")
This is a very basic model fine tuning process and the above process can be customized to train models on varied datasets like Text, PDF, Images, Video, etc using capabilities like · PyMuPDF, pdfplumber, PDFMiner, PyMuPDF, pdfplumber, PDFMiner, Whisper to extract and prepare data for LLM training.


Comments